CPU silently disappointed with your choice of instruction ordering
An adventure in CPU out-of-order instruction execution.
Pretend this is a distributed systems interview question. Assume x, y, r1 and r2 are all 0.
What are the possible values of r1 and r2?
Thread 1 Thread 2
x = 1 y = 1
r1 = y r2 = x
I expect you really want to add a lock, an atomic, a memory fence, something! Rust won’t even let you write code like this, so for the Rustaceans assume the variables are all Arc<AtomicU8> which we get and set with Ordering::Relaxed. But let’s continue, because I learnt a lot.
What values can r1 and r2 have?
- Either both threads run at the same time:
r1 == 1 && r2 == 1 - or Thread 1 runs all the way through first:
r1 == 0 && r2 == 1 - or Thread 2 runs all the way through first:
r1 == 1 && r2 == 0
What I did not expect BUT IT HAPPENED, is r1 == 0 and r2 == 0
Out-of-order example
If you’re doing Rust here’s an example that will give you r1 ==0 and r2 ==0 sometimes. If you don’t have Rust installed download the original C version here: ordering.zip. Make sure to run one of the versions. I didn’t believe it until I saw it.
// 1. Run it as is (SeqCst). Should be just timing output
// 2. Change the two HERE lines to Ordering::Relaxed and run it again.
// That should give lots of (seemingly impossible) memory reorderings.
use rand;
use std::sync::atomic::{AtomicU8, Ordering};
use std::sync::*;
use std::thread;
fn main() {
let x = Arc::new(AtomicU8::new(0));
let (x1, x2) = (x.clone(), x.clone());
let y = Arc::new(AtomicU8::new(0));
let (y1, y2) = (y.clone(), y.clone());
let r1 = Arc::new(AtomicU8::new(0));
let r11 = r1.clone();
let r2 = Arc::new(AtomicU8::new(0));
let r22 = r2.clone();
let enter = Arc::new(Barrier::new(3));
let (enter1, enter2) = (enter.clone(), enter.clone());
let exit = Arc::new(Barrier::new(3));
let (exit1, exit2) = (exit.clone(), exit.clone());
thread::spawn(move || {
loop {
enter1.wait(); // sync point, both threads at the starting line
while rand::random::<u32>() % 8 != 0 {} // delay arbitrarily so threads get out of sync
// x = 222
x1.store(222, Ordering::SeqCst); // HERE try changing this line to Ordering::Relaxed
// r1 = y
let y = y1.load(Ordering::SeqCst);
r11.store(y, Ordering::SeqCst);
exit1.wait(); // both threads pause, main thread checks the values of r1 and r2
}
});
thread::spawn(move || {
loop {
enter2.wait();
while rand::random::<u32>() % 8 != 0 {}
// y = 222
y2.store(222, Ordering::SeqCst); // HERE try changing this line to Ordering::Relaxed
// r2 = x
let x = x2.load(Ordering::SeqCst);
r22.store(x, Ordering::SeqCst);
exit2.wait();
}
});
let mut detected = 0;
let mut iterations = 1;
let start_run = std::time::Instant::now();
while start_run.elapsed().as_secs() < 5 {
// reset
x.store(0, Ordering::SeqCst);
y.store(0, Ordering::SeqCst);
// let both threads run a single iteration
enter.wait();
exit.wait();
// check if out-of-order execution happened
if r1.load(Ordering::SeqCst) == 0 && r2.load(Ordering::SeqCst) == 0 {
detected += 1;
println!(
"{} reorders detected after {} iterations",
detected, iterations
);
}
iterations += 1;
}
println!("{} per sec", iterations as f64 / 5.0);
}
The example sets up two threads and immediately blocks them on the enter barrier. If you’re not familiar with Rust, variables have to be cloned to be shared between threads, so think of enter1 and enter2 as aliases for enter. Similarly x1 and x2 are aliases of x, etc.
enter1.wait();
Once both threads are ready they each pause for a random amount of time to ensure each run is slightly different.
while rand::random::<u32>() % 8 != 0 {}
Then we run the example from the top of this post.
// x = 222, because 1 is boring
x1.store(222, Ordering::Relaxed); // try changing to Ordering::SeqCst
// r1 = y
let y = y1.load(Ordering::SeqCst);
r11.store(y, Ordering::SeqCst);
then we block the thread again to allow the main loop to check the results
exit1.wait();
The main loop runs for 5 seconds, each loop allows the threads to run a single time and then checks r1 and r2
while start_run.elapsed().as_secs() < 5 {
// reset
x.store(0, Ordering::SeqCst);
y.store(0, Ordering::SeqCst);
// let both threads run a single iteration
enter.wait();
exit.wait();
// check if out-of-order execution happened
if r1.load(Ordering::SeqCst) == 0 && r2.load(Ordering::SeqCst) == 0 {
detected += 1;
println!(
"{} reorders detected after {} iterations",
detected, iterations
);
}
iterations += 1;
}
and sure enough when we run it, there are re-orderings:
$ ./target/release/rtest
1 reorders detected after 217 iterations
2 reorders detected after 1148 iterations
etc
Time is an illusion - Superscalar CPUs
We can narrow down the problem by observing that:
- It doesn’t happen if you use a single core. On Linux:
taskset --cpu-list 1 ./target/release/rtest. - It also doesn’t happen with Rust memory ordering Ordering::SeqCst, or if you use a Mutex instead.
Modern CPUs are internally parallel (superscalar) within a single core. Here is a diagram of Intel’s 2013 era Haswell processors, from INF5063 at the University of Oslo
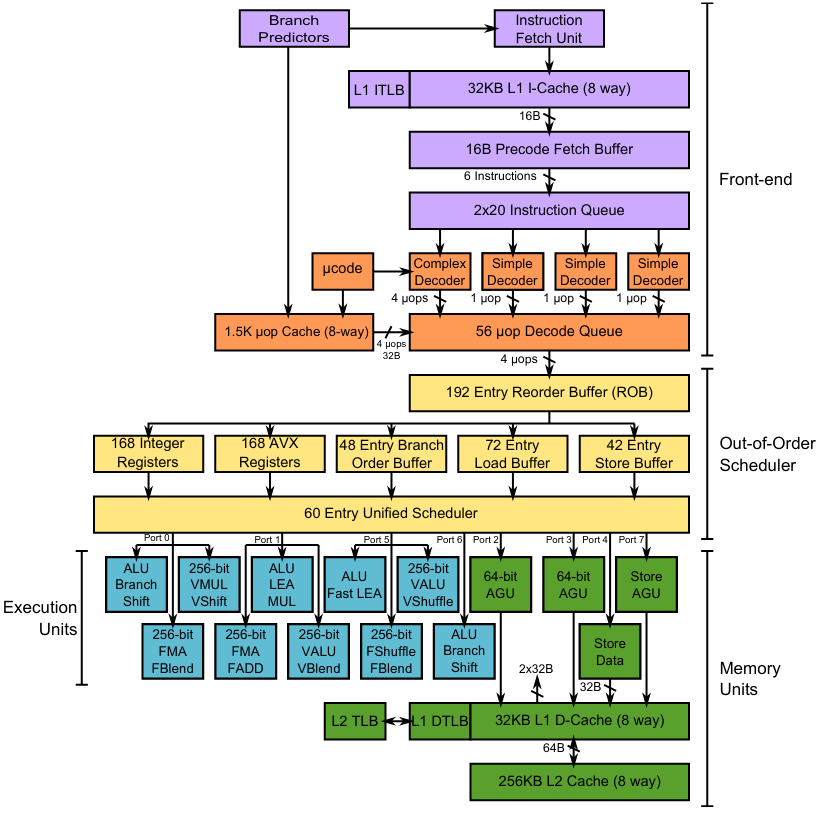
Each of the cyan “Execution Units” can execute an instruction at the same time. For example there are four ALUs (Arithmetic and Logic Unit), meaning a single Haswell processor core can execute an addition on four different variables in a single clock cycle. In parallel.
The processor fetches instructions, decodes them, fetches their operands and then dispatches them to a relevant port as soon as it is available. It does this for HUNDREDS of instructions AT THE SAME TIME. If an instruction is slow to load it’s operands (e.g. they must be fetched from memory vs are already in a register), the next operation in the program text will execute first. If an instruction requires a unit who’s port is busy, later instructions will execute first.
This means that from interview question, Thread 1 could very well run r1 = y before or concurrently with x = 1.
For a single-threaded program, or a single core machine THIS IS ALL COMPLETELY FINE. The CPU promises that you won’t notice any re-ordering. Compilers take advantage of the fact that you won’t notice and will also re-order instructions.
Space is an illusion - Memory hierarchy
Each CPU core has it’s own private memory (called L1 for Level 1) which is not shared with other processors or even with other cores on the same chip. It is very fast to access, much faster than shared memory (RAM). Ideally a processor will do most of it’s work with data that is in it’s L1 cache. This means that two cores can have different opinions on the value of a variable - the variable is in two places at once and has two different values.
At some point the shared cached will be written back to main memory, and all cores will come to a consistent view of a variable’s value. For a single thread it doesn’t matter when this happens.
Muti-core - there be dragons
The problems occur when you have more than one core. The promise that re-ordering will be invisible to you does not extend across cores. Memory caches are not shared across cores. To return to our interview question, each core is free to re-order the operations to this:
Thread 1 Thread 2
r1 = y r2 = x
x = 1 y = 1
Those operations are safe within each core, but because we are wildly and irresponsibly sharing memory they are not safe in a multi-core setup. That’s the instruction order that gives us r1 == 0 and r2 == 0.
Even without instruction re-ordering we could observe the same behavior because of the multiple L1 caches:
- Thread 1 and Thread 2 set x and y to 1, but each core only updates it’s L1 cache, and does not write back to main memory yet (because that would take forever).
- Thread 1 will still see y as 0, and Thread 2 will see x as 0, because they both really are 0 in main memory.
Which is why we need synchronization primitives. Happy locking!
Sources
I started looking into this because I was unsure what Rust Ordering to use with my atomics. In Go sync/atomic is always sequentially consistent so I haven’t had to worry about it before (ref 1, ref 2, ref 3).
I did some benchmarking on this example. On Linux I tried Relaxed, SeqCst, and replacing it all with a Mutex. All three took very similar amounts of time.
Jeff Preshing’s Memory Reordering Caught in the Act answered all my questions. A great article to read next. This post is very heavily inspired by that one.
Here’s a fascinating Stack Overflow answer on this topic.
The University of Oslo course on Programming heterogeneous multi-core processors (PDF) where I got the diagram.
David Kanter on Haswell’s Microarchitecture which also uses the Oslo diagram (or vice versa?). A very in-depth article. Possibly too in-depth.
My Rust code is adapted from Cormac Relf’s version of Jeff Preshing’s code.
The original example comes from section 8.2.3.4 of the Intel 64 and IA-32 Architectures Software Developer’s Manual Volume 3: System Programming Guide. Thanks.